

Crawl là gì? Đây là câu hỏi của nhiều Marketer khi mới bắt đầu tìm hiểu về SEO hay phát triển nội dung trên website. Vậy Crawl website hoạt động như nào? Công cụ này đóng vai trò gì trong việc gia tăng thứ hạng, đánh giá điểm chất lượng trên website? Hãy cùng CAS SOLUTION tìm hiểu ngay trong bài viết dưới đây nhé!

Crawl là gì?
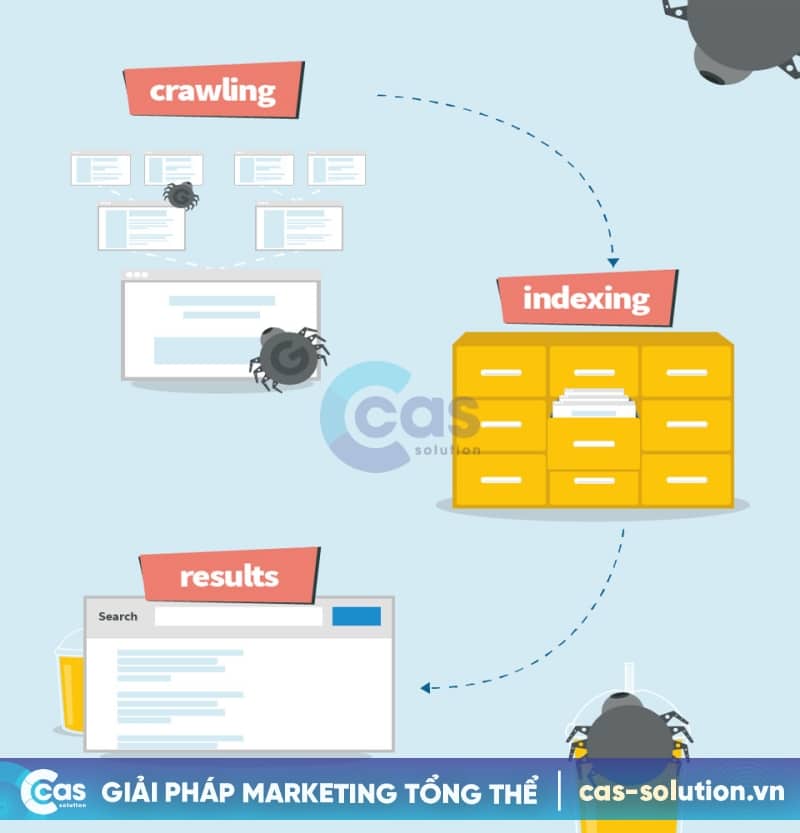
Crawl là gì? Google Crawl (searchbot, spider hay bộ thu thập dữ liệu) là một phần mềm mà Google và các công cụ tìm kiếm khác sử dụng để quét trang Web. Nói một cách đơn giản, nó “thu thập” dữ liệu web từ trang này sang trang khác, tìm kiếm nội dung mới hoặc nội dung cập nhật mà Google chưa có trong cơ sở dữ liệu của mình.
Song, bất kỳ công cụ tìm kiếm nào cũng có bộ trình thu thập thông tin riêng. Đối với Google, có hơn 15 loại trình thu thập thông tin khác nhau và trình thu thập thông tin chính của Google được gọi là Googlebot. Googlebot thực hiện cả thu thập thông tin và lập chỉ mục, đó là lý do tại sao chúng ta sẽ xem xét kỹ hơn cách thức hoạt động của nó.
Ví dụ, Crawl Google search results đóng vai trò quan trọng trong quá trình tìm kiếm, hiểu đơn giản nó hoạt động theo các bước như:
- Bạn xuất bản hoặc cập nhật nội dung trên trang web của bạn.
- Bot sẽ tìm kiếm và thu thập các trang mới hoặc đã cập nhật trên trang web của bạn.
- Google lập chỉ mục các trang mà trình thu thập thông tin tìm thấy.
- Google sẽ hiển thị trang của bạn trong kết quả tìm kiếm dựa trên mức độ liên quan của nó với truy vấn của người dùng.

Tuy nhiên, những công cụ tìm kiếm không phải là nơi duy nhất sử dụng “crawl data from website”. Bạn cũng có thể tự triển khai crawl dữ liệu website để thu thập những thông tin về các trang web.
Một số trình thu thập dữ liệu công khai có đôi chút khác biệt so với các trình thu thập dữ liệu của các công cụ tìm kiếm như Google Bot hoặc Bingbot. Nhưng chúng hoạt động theo cách tương tự như các trình thu thập dữ liệu của các công cụ tìm kiếm.
Và bạn có thể sử dụng thông tin từ các loại crawl dữ liệu này để cải thiện trang web của mình. Hoặc để hiểu rõ hơn về các trang các web khác.
Cách thức hoạt động của Crawl là gì?
Tiếp theo chúng ta sẽ tìm hiểu sâu hơn về cách thức hoạt động thu thập dữ liệu trên Google khi quét 3 yếu tố chính trên một trang web: nội dung, mã và liên kết ngay bên dưới.
Bằng cách “crawl data from website”, bot có thể đánh giá nội dung của trang. Thông tin này giúp thuật toán Google xác định trang nào có câu trả lời mà người dùng đang tìm kiếm. Đó chính là lý do tại sao việc sử dụng từ khóa SEO phù hợp luôn đóng vai trò quan trọng, giúp cải thiện khả năng kết nối trang đó với các tìm kiếm liên quan của thuật toán.
Tiếp đó, trong khi đọc nội dung của một trang các spider website cũng thu thập mã HTML của trang đó. Lúc này bạn có thể sử dụng một số mã HTML nhất định (như thẻ meta) để giúp bot crawl data thu thập nội dung, mục đích của trang.
Các trình thu thập thông tin cần phải tìm kiếm hàng tỷ trang web. Để thực hiện điều này, chúng đi theo các đường dẫn. Các đường dẫn đó phần lớn được xác định bởi các liên kết nội bộ.
Nếu website A liên kết đến website B trong nội dung, bot có thể theo dõi liên kết từ website A đến website B. Sau đó xử lý website B.
Đây là lý do tại sao liên kết nội bộ lại quan trọng đối với SEO. Nó giúp trình thu thập thông tin của công cụ tìm kiếm tìm và lập chỉ mục tất cả các trang trên trang web.

Tầm quan trọng của crawl dữ liệu trong SEO
Sau khi hiểu được định nghĩa và cách thức hoạt động, các marketer hoặc người làm SEO nên biết được tầm quan trọng của crawl là gì để có thể có định hướng phát triển chiến lược SEO tốt nhất cho website của mình. Quá trình crawl dữ liệu giúp:
Điều hướng website của bạn đi đúng hướng phát triển
Crawl data from website có thể cho bạn biết chính xác mức độ dễ dàng để bot Google điều hướng và xử lý nội dung trên website. Ví dụ, nhờ vào việc quét website bạn có thể tìm ra được các vấn đề ngăn chặn việc crawl dữ liệu hiệu quả như chuyển hướng tạm thời, nội dung trùng lặp,…
Bên cạnh đó, việc crawl dữ liệu có thể giúp bạn sớm phát hiện ra những trang mà Google không thể lập chỉ mục để tìm ra nguyên nhân, cách khắc phục. Điều này giúp tránh nguy cơ mất thời gian, tiền bạc và ảnh hưởng đến thứ hạng SEO của web.

Xác định các liên kết bị hỏng để cải thiện sức khỏe của trang web và giá trị liên kết
Liên kết hỏng là một trong những lỗi phổ biến nhất. Chúng gây phiền toái cho người theo dõi bài viết, hay muốn tìm hiểu một nội dung nào đó trên website. Để crawl dữ liệu qua trình thu thập dữ liệu web Google là một cách thức tuyệt vời để rà soát các lỗi này, giúp tìm ra nhanh chóng các liên kết bị hỏng và sửa lại để đảm bảo website hoạt động ổn định.
Song, khi phát hiện các liên kết hỏng bạn có thể khắc phục bằng cách: xóa liên kết, thay thế liên kết hoặc báo cáo sự cố với chủ sở hữu trang web liên kết nếu đó là liên kết ngoài.

Tìm nội dung trùng lặp trên hệ thống nội dung hiển thị
Nội dung trùng lặp là nội dung giống hệt hoặc gần giống nhau. Khi sử dụng công cụ crawl google search results kiểm tra trang web có thể giúp bạn tìm ra nội dung trùng lặp.
Những nội dung này có thể gây ra các vấn đề SEO nghiêm trọng, gây nhầm lẫn cho các công cụ tìm kiếm. Nó cũng có thể khiến phiên bản trang không đúng hiển thị trong kết quả tìm kiếm hoặc thậm chí bộ máy đọc của Google có thể nhầm lẫn trong việc bạn có đang sử dụng các hoạt động thao túng gian dối hay không.
Sau khi xác định được nội dung cần chỉnh sửa, bạn có thể chỉnh sửa lại để phù hợp hơn với kết quả tìm kiếm.

Các yếu tố ảnh hưởng đến việc ra quyết định crawl data from website của Google
Không có lịch trình cụ thể về thời điểm Google thực hiện crawl data from website của bạn. Điều này có thể ví như một cuộc ghé thăm ngẫu nhiên khi bộ máy của Google “lê la” khắp khu vực chúng hoạt động.
Tuy nhiên, một số yếu tố có thể ảnh hưởng đến tần suất truy cập, rà soát của Google bao gồm:
- Kích thước trang web lớn, có nhiều trang, hệ thống nội dung, thông tin lớn và có lượng truy cập thường xuyên cao.
- Mức độ phổ biến của trang: Nếu trang web của bạn có số lượng liên kết inbound cao từ các nguồn uy tín, Google sẽ coi đây là tín hiệu của một tài nguyên chất lượng, có khả năng dẫn đến việc thu thập dữ liệu thường xuyên hơn.
- Tốc độ của website: Một trang web tải nhanh sẽ dễ dàng hơn cho Googlebot thu thập dữ liệu.
- Độ mới, sáng tạo của nội dung: Nếu bạn liên tục cập nhật nội dung mới, có liên quan trên trang web của mình thì Google có khả năng sẽ ghé thăm thường xuyên hơn để cập nhật chỉ mục.
Một số lỗi thường gặp khi “crawl data from website”
Ngoài việc tìm hiểu crawl là gì, cách thức hoạt động, tầm quan trọng của việc quét dữ liệu thì trong bài viết này CAS Solution sẽ cùng bạn tìm hiểu về một số lỗi thường gặp khi trình thu thập dữ liệu của công cụ tìm kiếm không thể điều hướng qua các trang web theo cách thông thường. Một số lỗi phổ biến như:
- Bị chặn bởi robots.txt: Website hoặc một số trang con trên trang web có thể bị chặn bởi một lệnh trong tệp Robots.txt. Điều này ngăn chặn Googlebot hoặc các công cụ tìm kiếm khác thu thập thông tin các trang đó.
- Lỗi Error 404: Trang trả về lỗi 404 không thể thu thập dữ liệu. Lỗi này có thể xảy ra khi các trang bị xóa hoặc URL của chúng được thay đổi mà không có hướng dẫn phù hợp.
- Lỗi máy chủ: Nếu máy chủ thường xuyên hoạt động liên tục hoặc phản hồi chậm, Googlebot có thể gặp sự cố khi thu thập trang web dữ liệu của bạn.
- Trang web quá chậm: Nếu trang web tải quá chậm, Googlebot có thể bỏ cuộc trước khi thu thập dữ liệu xong. Điều này chủ yếu áp xuất hiện khi trang web chậm một cách khó hiểu.
- Lạm dụng thẻ meta: Việc sử dụng thẻ meta noindex hoặc nofollow không chính xác cũng có thể ngăn chặn Google thu thập dữ liệu trang web của bạn.

Làm thế nào để tăng khả năng thu thập thông tin?
Nói chung, để website hoạt động và tăng trưởng bền bỉ, người vận hành web cần phải làm cho crawl dữ liệu từ công cụ tìm kiếm càng nhiều càng tốt. Dưới đây là một số điều có thể thực hiện để tăng khả năng thu thập dữ liệu của trang web như:
- Tạo ra nội dung chất lượng cao được cập nhật thường xuyên
- Cải thiện tốc độ hoạt động của trang web nhanh nhất có thể
- Kiểm tra các liên kết nội bộ để điều hướng tốt hơn
- Sử dụng các cụm từ khóa trọng tâm, tối ưu hóa hình ảnh và văn bản thay thế
- Tạo và gửi sitemap.xml để đảm bảo rằng trình thu thập thông tin không bị nhầm lẫn, bỏ sót việc lập chỉ mục các trang quan trọng.
- Thiết kế trang web của bạn thân thiện với thiết bị di động
Tóm lại, trình thu thập dữ liệu chính của Google, Googlebot, hoạt động theo các thuật toán phức tạp, nhưng bạn vẫn có thể “điều hướng” hành vi của nó để làm cho nó có lợi cho trang web của bạn. Bên cạnh đó, hầu hết các bước tối ưu hóa quy trình thu thập dữ liệu đều lặp lại các bước của SEO chuẩn mà chúng ta đều quen thuộc.
Trên đây, những thông tin giải đáp về crawl là gì và một số khía cạnh của việc crawl dữ liệu trên các công cụ tìm kiếm. Cảm ơn bạn đã dành thời gian tham khảo bài viết của CAS SOLUTION. Để được tư vấn về dịch vụ chăm sóc website, vui lòng liên hệ tới hotline để được hỗ trợ nhanh nhất. Chúc bạn luôn thành công trong lĩnh vực kinh doanh của mình!
More Articles Like This
Công cụ tìm kiếm là gì? Các công cụ tìm kiếm phổ biến nhất thế giới
Công cụ tìm kiếm là gì? Bạn có bao giờ tự hỏi làm thế nào mà chỉ với vài từ khóa, hàng triệu kết quả tìm kiếm xuất hiện trước mắt bạn chưa? Đó chính là nhờ vào những công cụ thông minh gọi là máy tìm kiếm. Công cụ tìm kiếm (hay còn gọi là
Facebook Audience Custom: Hướng dẫn chi tiết từ A đến Z để tạo ra tệp khách hàng vàng
Trong thời đại số, việc tiếp cận khách hàng một cách hiệu quả là điều vô cùng quan trọng. Và Facebook Audience Custom chính là công cụ đắc lực giúp bạn làm điều đó. Muốn tăng tỷ lệ chuyển đổi và doanh thu? Custom Audience là giải pháp bạn cần. Facebook Audience Custom là gì?
Checkpoint Facebook là gì? Cách mở khóa và phòng tránh hiệu quả
Bạn có bao giờ gặp phải tình huống tài khoản Facebook của mình bị khóa bất ngờ? Đó có thể là do Checkpoint – một tính năng bảo mật của Facebook. Hãy cùng tìm hiểu Checkpoint là gì, tại sao nó lại xảy ra và cách để giải quyết tình huống này. Checkpoint là gì?